数据结构中的栈和队列
发表于 · 归类于
代码 · 阅读完需 7 分钟 ·
报告错误
这篇文章浅显的介绍了在数据结构中如何定义栈和队列的抽象数据类型(Abstract Data Type),以及基于这种抽象数据类型的一些操作:入栈,出栈,取栈顶元素,入队,出队,取队首元素和队尾元素等。
一、引言
栈和队列是计算机科学领域中经常使用的两个概念,从操作系统的事务管理机制到一个小的递归程序,都离不开这两个概念。
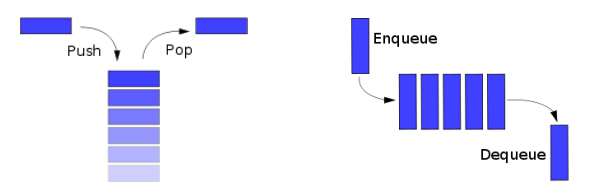
栈因为它的后进先出(LIFO)而给人们留下了深刻的认识。假如你把一连串的数据插入到栈之中,然后再把他们取出,那么你会得到一个和你输入相反的结果。比如输入的数据是 {20, 15,10, 5},那么你从栈中取得的数据将是 {5, 10, 15, 20}。
队列却有着和上面描述截然相反的特征。当你向队列中输入 {20, 15, 10, 5} 时,你得到的结果依然是 {20, 15, 10, 5}。这就是队列先进先出(FIFO)的特点。
下图形象的描述了栈和队列的这些特点:
二、栈和队列的抽象数据类型
栈和队列特殊,然而它们依旧是表(Lists)的两种分支,我们依然可以用定义表的方法来定义栈和队列。下面是采用链式存储结构定义的栈和队列:
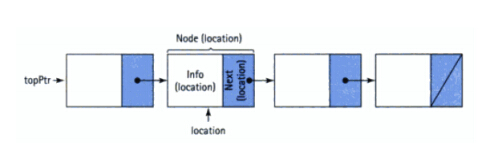
typedef struct SNode // 栈的节点结构
{
char data;
struct SNode *next;
} SNode, *LinkStack;
typedef struct // 栈的表头结构
{
int count;
struct SNode *top;
} Stack;
typedef struct QNode
{
char data;
struct QNode *next;
} QNode, *LinkQueue;
typedef struct
{
struct QNode *front;
int count;
struct QNode *rear;
} Queue;
这种 ADT 的优点在于,充分的利用了头结点数据域的内存空间,用来存放节点的数量。
三、栈的基本操作
三个基本的栈操作是:入栈(push),出栈(pop)和取栈顶元素(stack top)。入栈是将一个数据压入栈顶,出栈是将栈顶元素弹出,取栈顶元素是得到栈顶元素的操作(它和出栈的区别在于,没有删除栈顶元素)。
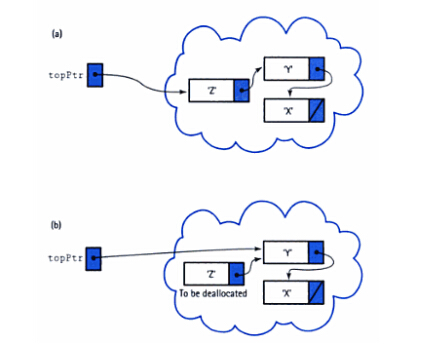
下图是链式栈的出栈示意图:
int pushStack(Stack &S, char dataIn)
{
LinkStack newPtr;
newPtr = (LinkStack)malloc(sizeof(SNode));
newPtr->data = dataIn;
newPtr->next = S.top;
S.top = newPtr;
S.count++;
return 1;
}
int popStack(Stack &S, char &dataOut)
{
LinkStack dltPtr;
dltPtr = S.top;
dataOut = S.top->data;
S.top = S.top->next;
S.count--;
free(dltPtr);
return 1;
}
取栈顶元素 Top 则是访问栈顶元素而得到的一个数据。
创建一个空栈是很容易的,我们只需要建立一个头结点 Stack,它的数据域用来存放这个栈的结点数目(初始情况为 0),next 指针指向 NULL 即可。Push 是作为向链表前端进行插入而实现的,其中表的前端是指栈顶。Pop 同样是通过删除表的前端(栈顶)元素而实现的。
四、队列的基本操作
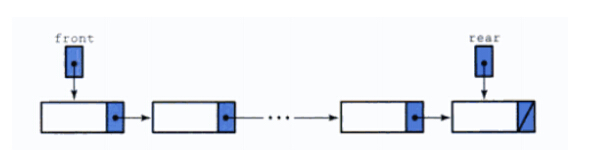
入队,出队,取队首元素和队尾元素是队列的四种基本操作。入队和出队是构造队列或者销毁队列时采取的两种操作,它们或者增加或者减小了队列的规模,下图是链式队列的入队和出队示意图。
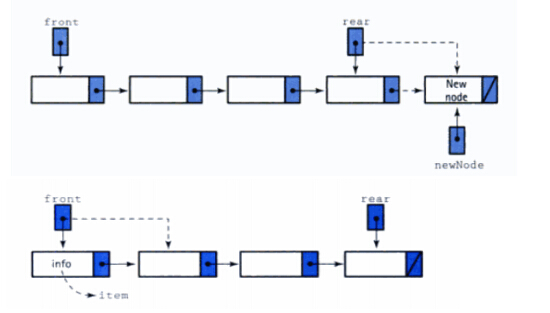
int enQueue(Queue &Q, char dataIn)
{
LinkQueue newPtr;
newPtr = (LinkQueue)malloc(sizeof(QNode));
newPtr->data = dataIn;
newPtr->next = NULL;
if (Q.count == 0) // 向空队列中插入时
Q.front = newPtr;
else // 插入一条数据并且更新表头信息
Q.rear->next = newPtr;
Q.rear = newPtr;
Q.count++;
return 1;
}
int deQueue(Queue &Q, char &dataOut)
{
LinkQueue deleteLoc;
if (Q.count == 0)
return 0;
dataOut = Q.front->data;
deleteLoc = Q.front;
if (Q.count == 1)
Q.rear = NULL;
Q.front = Q.front->next;
Q.count--;
free(deleteLoc);
return 0;
}
取队首元素和队尾元素是在不破坏队列原有结构的基础上进行的操作。
return Q.front->data;
return Q.rear->data;
五、结束语
栈和队列是数据结构中重要的两个概念,深入的了解它们,对计算机的进一步学习(比如,了解操作系统运行机制,或者编译原理)有着重要的作用。
六、参考资料
- Richard F.Gilberg, Behrouz A.Forouzan,数据结构的 C++伪码实现,人民邮电出版社
- 严蔚敏,数据结构,清华大学出版社
- 数据结构实验指导书
- Stack (data structure) - Wikipedia
- Queue (data structure) – Wikipedia